Work Flow#
This section would explain the details of how SmoothCrawler-Cluster could run many crawlers with each others as one or more cluster(s) with *Work Flow.
In the each single crawler instance of SmoothCrawler-Cluster, it would run as different roles, may be Runner or Backup Runner. So it also divides to 2 types role to explain their details of work flow later. But it would explain the work flow of entire cluster running first. Let you understand the brief of the cluster running, and give you more the details of each sections (running of each roles).
Life Cycle#
Here is the brief of cluster running:
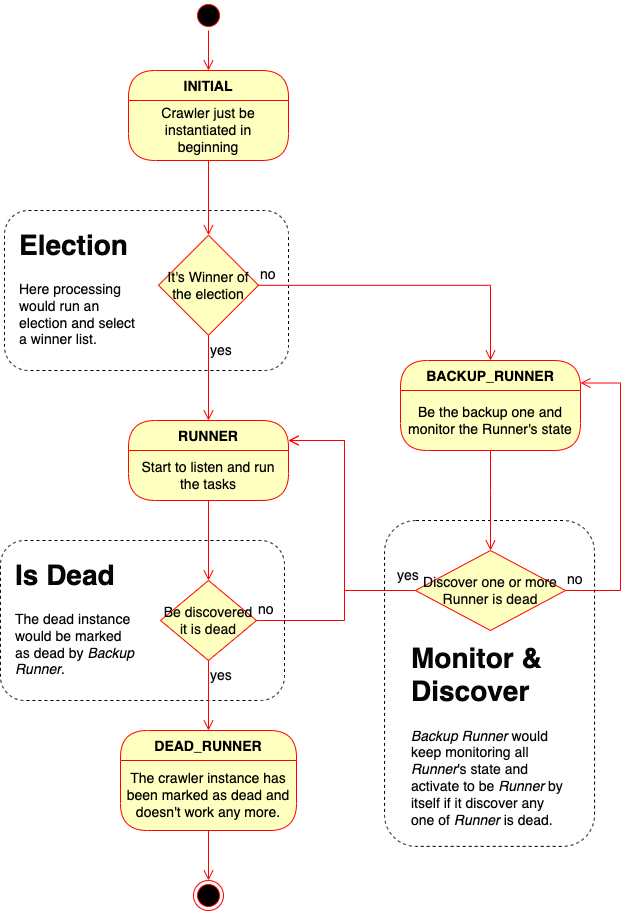
Let’s explain the details step by step as below.
Brief of cluster running#
1. Initial (INITIAL state)#
First of all, every crawler instance runs 2 thing in initialization: register meta-data objects to this cluster and run election. Every crawler instance creates its every states as meta-data objects and registers them to cluster to let system could know the state of each one crawler instances.
See also
What exactly meta-data objects are?
Please refer to Meta-Data Modules to get more details of meta-data in SmoothCrawler-Cluster.
2. Run election (INITIAL state)#
When it’s ready for running election, it runs the election to decide to which is/are Runner in cluster.
In generally, it returns Election Result to let every candidates to know whether they’re Winner or not. If it’s Winner, it would be the one of Runner in cluster.
3-1. As a Runner (RUNNER state)#
If it’s Winner of the election, it runs as Runner from now on. It only has 2 types results: keep be alive or dead. Keep be alive for doing Runner’s job or occur any problems lead to be dead.
About more details of Runner, please refer to Runner.
3-2. As a Backup Runner (BACKUP_RUNNER state)#
The rest which is/are not Winner of the election, it runs as Backup Runner from now on. It keeps monitoring all Runner instances and check their meta-data values. If it exists any one of Runner is dead, it would activated to be a Runner by itself quickly.
About more details of Runner, please refer to Back Runner.
Now, I believe you get the drift of the work flow of crawler cluster with SmoothCrawler-Cluster. The following part will be discussed in the each one role’s work flow.
Role’s work flow#
Once again, if the crawler instance is Winner of the election, it would be the Runner in cluster. And it starts to run as a Runner from now on. Here explain the details of what things it would to do if it is a Runner.
Runner#
Here is the work flow with details of Runner:
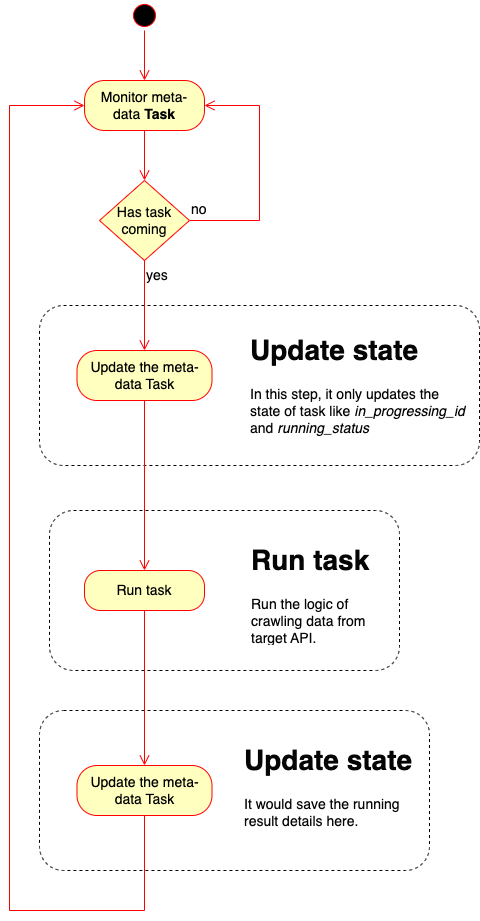
It has 4 major things it would run: Monitor task, Update Meta-Data, Run task and Update Meta-Data.
Monitor task#
It keeps monitoring to check whether it has any task comes in or not by meta-data Task. If it doesn’t, it would keep doing; if it does, it would run the task and back to monitor after finish it.
Update Meta-Data#
If it detects any task come in, it would update the meta-data Task first before start to run it for recording the crawler’s state.
Run task#
Run the tasks to crawl something with API. The things this step does are what we need to implement. So all your SmoothCrawler components would be run here.
Update Meta-Data#
Whether it finishes the tasks or it doesn’t, it updates meta-data Task to save the running results or errors.
After it done the above tasks, it would back to first step — keeps monitoring and check meta-data Task to wait for next tasks.
Back Runner#
Here is the work flow with details of Backup Runner:
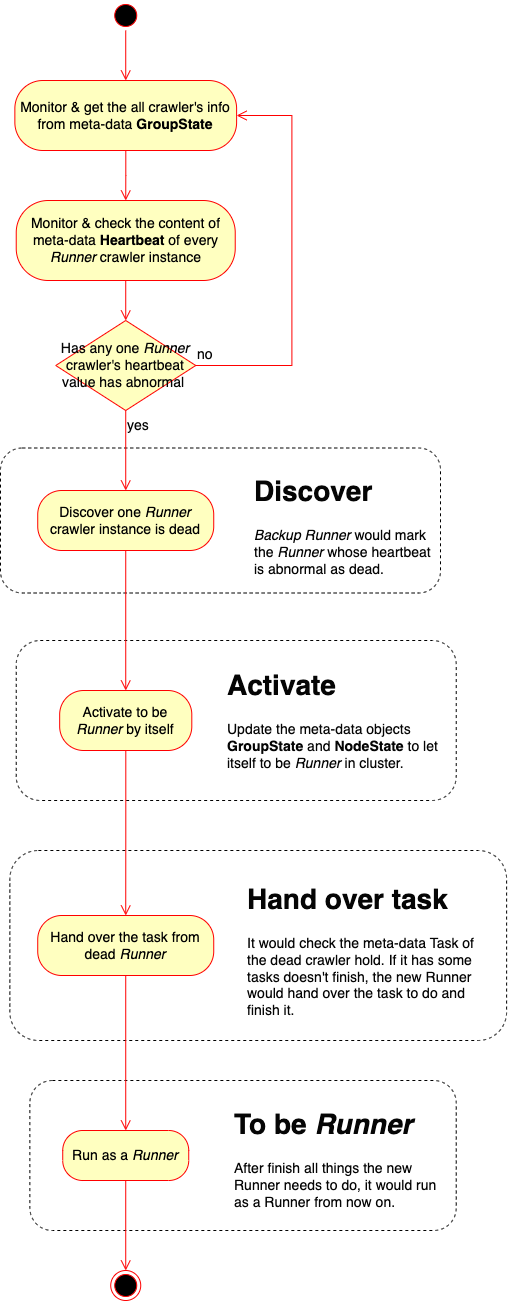
It has 5 major things it would run: Monitor heartbeat, Discover dead Runner, Activate to be Runner, Hand over the task and Run as Runner.
Monitor heartbeat#
It keeps monitoring 2 meta-data: GroupState and each one’s Heartbeat. It would get the all crawler instance’s info by monitoring GroupState, and it would monitor and check each one’s detail value of Heartbeat.
Note
What’s the criteria for checking?
The current UTC date and time minus Heartbeat.heart_rhythm_time should NOT be longer than Heartbeat.update_timeout.
If it occurs timeout of value Heartbeat.heart_rhythm_time, it should be reach the threshold of Heartbeat.heart_rhythm_timeout within next 10 times, nor it would reset the timeout records and records it from 0.
Discover dead Runner#
Discover that it exists dead Runner in cluster. So it marks the dead one’s role as Dead Runner and also marks its heartbeat state as ASYSTOLE to notice the cluster should eliminate the dead one and activate the current backup one.
Activate to be Runner by itself#
It would update the meta-data GroupState and NodeState to activate itself to be a Runner in the cluster.
Hand over the task from dead Runner#
After the Backup Runner be activated to Runner, it would hand over the tasks from dead Runner, aka the crawler whose role is Dead Runner, and new Runner one would run the task if it doesn’t be mark as DONE.
Run as Runner from now on#
Finally, it runs as Runner from now on. So the work flow would turn to run as Runner.